About me

Mechanical Engineer | Web Developer | Data Enthusiast
Hi there! I'm a mechanical engineering graduate who ventured into web development and discovered a passion for data science along the way. For nearly two years, I've been building websites and applications using frameworks like Vue, React, and Next.js, making projects smoother and more efficient.
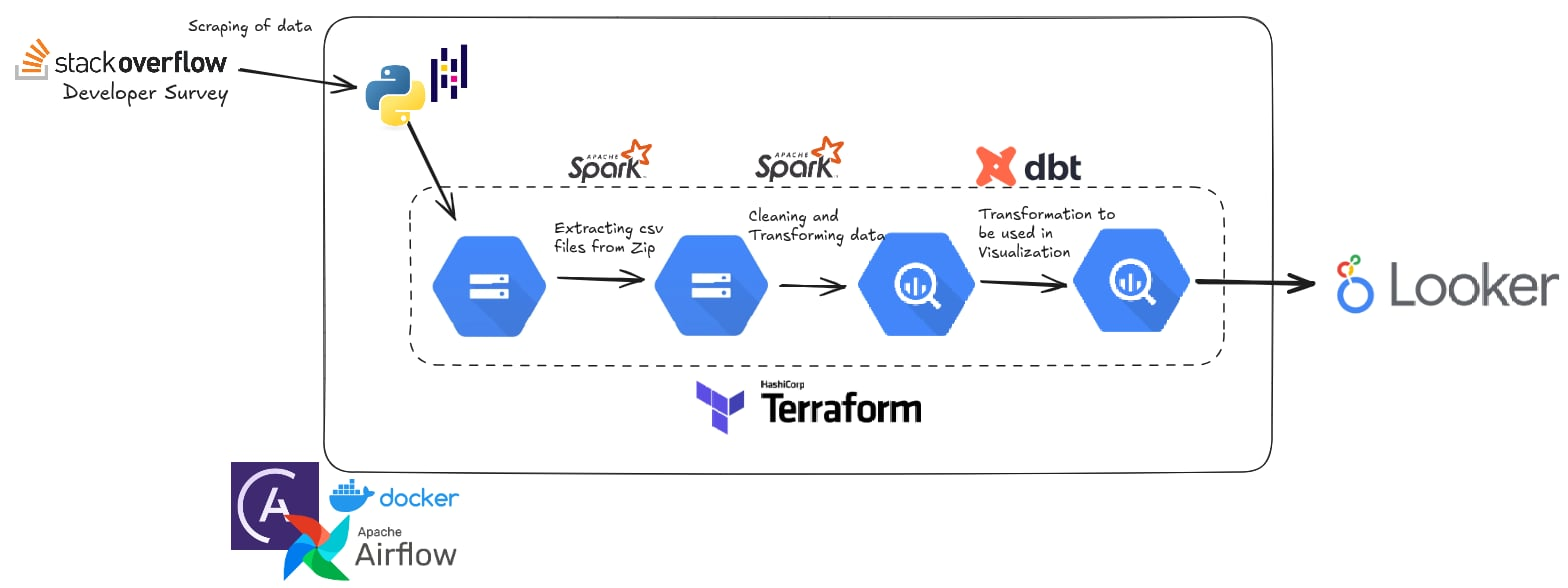
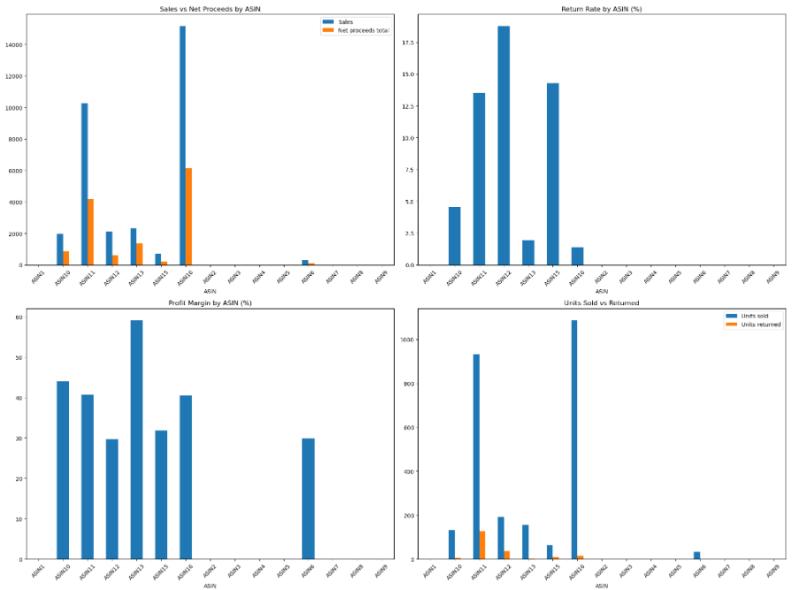
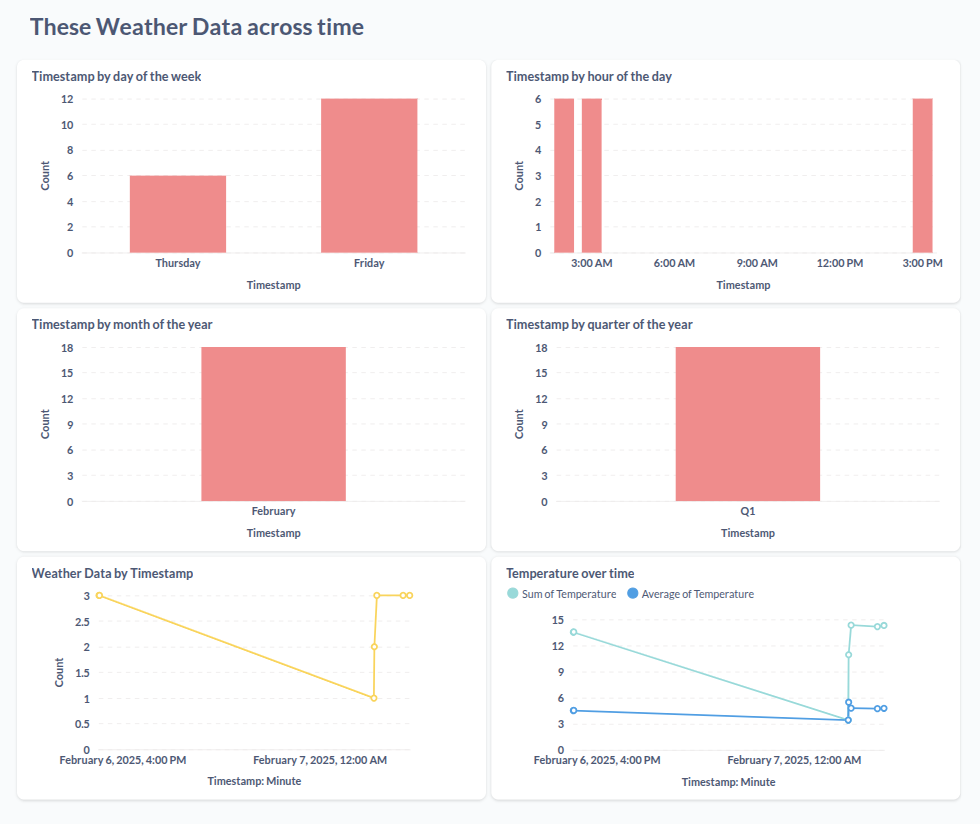
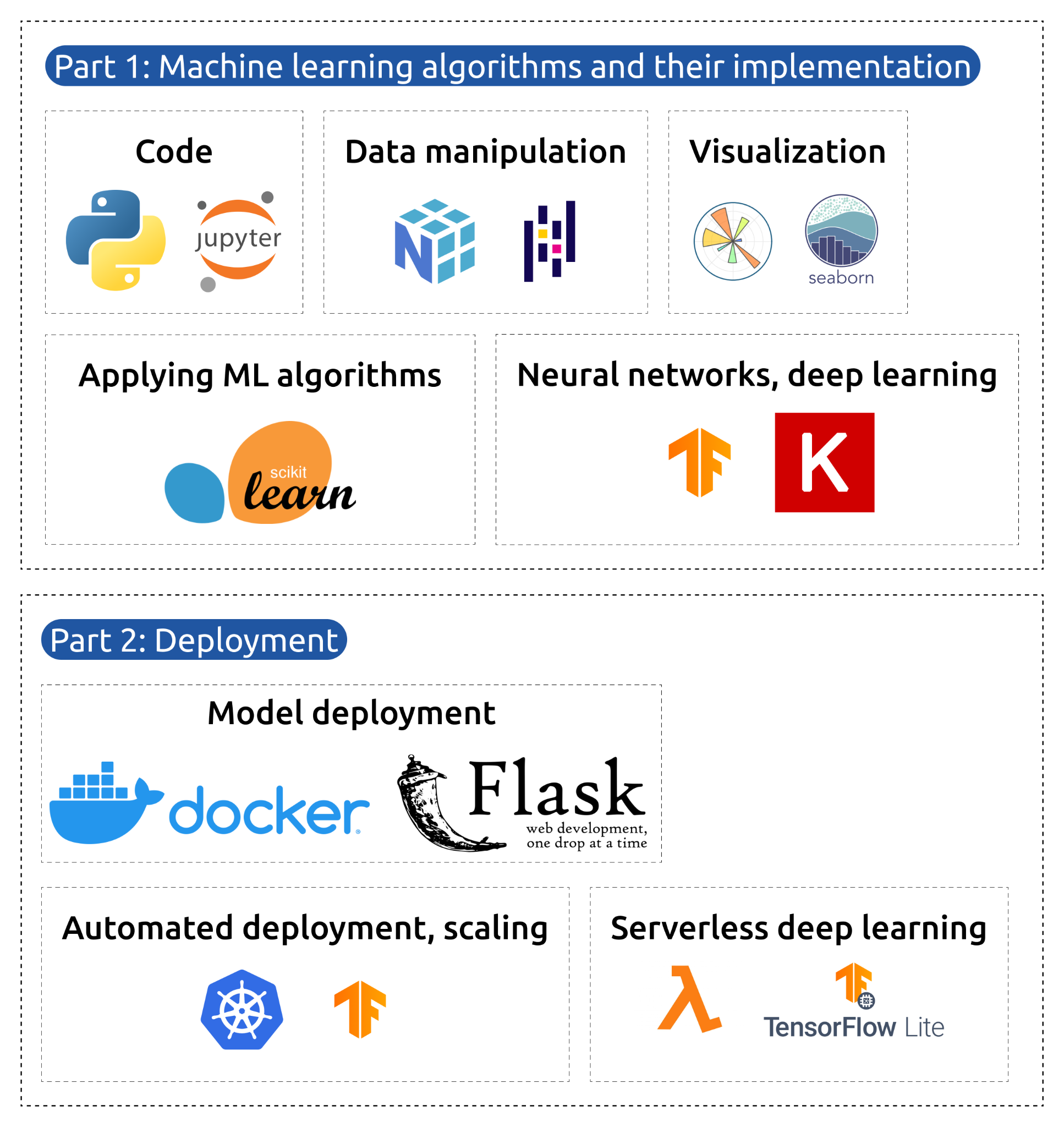
These days, I'm diving deeper into data science, machine learning fundamentals and data engineering—learning how to create and maintain data pipeline, build, evaluate, and deploy models, as well as discovering new ways to bring data insights into development. I love how data combines engineering and analytics to solve real-world problems, and I'm excited about how these skills can enhance my work even more.
Outside of coding, you'll usually find me with a light novel, manga, or manhwa, or enjoying coffee shop vibes while exploring the latest in tech.
Let’s connect if you're into data, development, or just want to chat about new tech trends!
View Resume